前回に引き続き、メイドさんにプログラミングを教えるためのシリーズです。
今回は前回までとうってかわって、Webサーバーの仕組みを説明します。Androidアプリを使っていると「この部分はサーバーが必要だ」「ウェブサーバーを立てよう!」という言葉をよく聞くと思います。
「ウェブ」って、「ホームページ」とか見るための仕組みではないでしょうか?なぜ、スマートフォンアプリにWebサーバーが必要なのか?Webサーバーを立てると何ができるのか、アプリ開発視点で見ていきたいと思います。
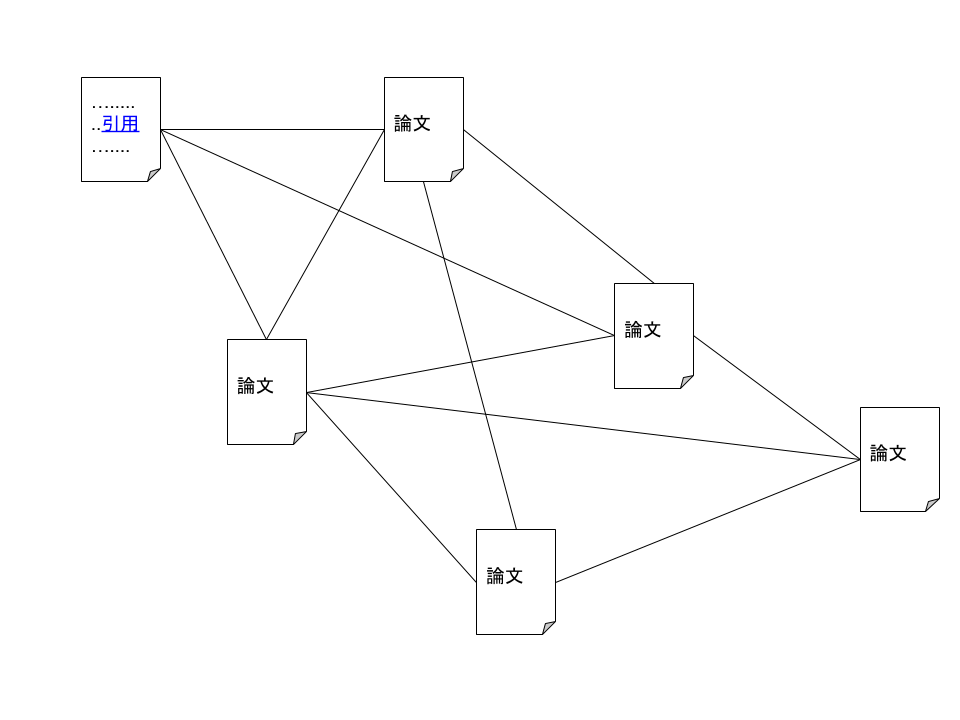
WWW(World Wide Web)は、世界中の論文をリンクする仕組みだった
昔々、と言っても1990年代なのですが、Timさん (Tim Berners-Lee)という人が、現在私達が「インターネット」だと思っている世界を考えました。
World Wide Webと名付けられたそれは、当時、できたてほやほやの「The Internet」を使って、論文を公開する仕組みとして設計されたものでした。
論文は他の論文を引用します。引用先はワンクリックでジャンプできたら便利です。そこで、引用先にリンクできる仕組みを「ハイパーリンク」を実現するテキスト文書「ハイパーテキスト」が誕生しました。「HTML」です。これは
<a href="リンク先">リンクテキスト</a>
のように書くと、他の文書にリンクできる画期的な書式でした!
Webとはくもの巣という意味です。文書と文書がリンクによってくもの巣のように世界中に張り巡らされている!それがワールドワイドなウェブの目指す世界だったのです。
この世界を実現するために、論文を読むためのソフト(Webブラウザー)と、論文を配信するホストコンピュータ(Webサーバー)が作られました。WebブラウザーとWebサーバーは互いに通信をします。通信をするための決まりごとを「プロトコル」と言います。Web専用のプロトコルとして、「HTTP (Hyper Text Transfer Protocol)」が作られました。
用語のおさらい
| 用語 | 意味 |
|---|---|
| World Wide Web | Timさんが考えた「The Internet」上の論文配信ネットワーク |
| ハイパーリンク | 論文から引用先論文にジャンプする画期的機能 |
| ハイパーテキスト(HTML) | ハイパーリンクを実現するための文書形式 |
| Webサーバー | 論文を配信するサーバー |
| Webブラウザ | 論文を閲覧するためのソフト |
| プロトコル | 通信をするための決まりごと |
| HTTP | WebサーバーとWebブラウザの間で行われる通信のプロトコル |
HTTPの仕組み
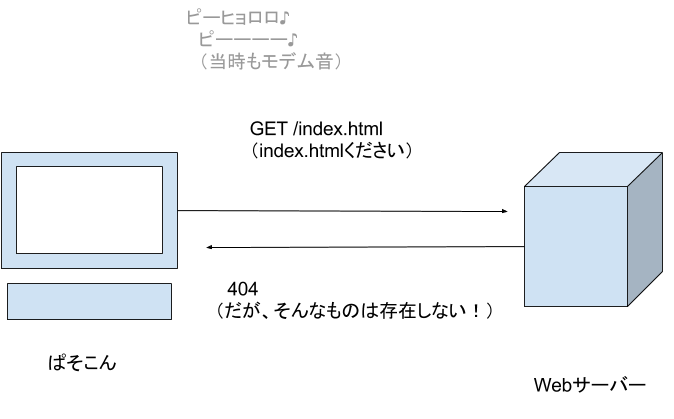
論文をサーバーから貰うには、次の情報が必要です。
- 論文のファイル名
論文を取得する命令をGETと名付けられました。
GET /folder/hogehoge.html
この命令(「HTTPリクエスト」と言います)を受け取ったWebサーバーは、folderの中にhogehoge.htmlがあれば次の情報を返します。
- 「あったよ!」という情報
- hogehoge.html の内容
これらを合わせて「HTTPレスポンス」と言います。
そのうち、前者を「ステータスコード」と言います。これは数字3桁によって定められていて、例えば次のように決まっています。
- 200: OK (あったよ!)
- 400: BAD REQUEST(リクエストが間違ってるよ!)
- 404: NOT FOUND(そんなファイル無いよ!)
- 500: INTERNAL SERVER ERROR(ごめん、サーバーでエラーが起きちゃった(汗;)
- 503: Service Unavailable(ごめん、今混んでるみたいだ!後でもう一度来て!)
とてもシンプルな仕組みですね!
WebサーバーがHTMLを自動生成しても良い
Webサーバーは、Webブラウザーから、リクエストを受け取ったら、ステータスコードと、HTMLページを返せば良いのです。HTMLページは、サーバーのディスク上に、HTMLファイルとして置いておくことが最もシンプルですが、別に、ファイルがなくても、その場でプログラムで作ってしまっても良いのです!
Webリクエストを受け取ったWebサーバーが、プログラムを動かす仕組みとして、CGI (Common Gateway Interface) という物が作られました。
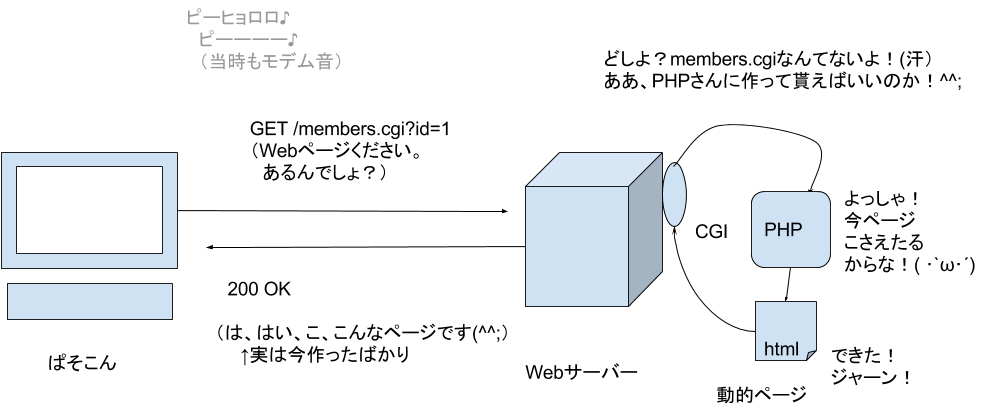
プログラムによって毎回違うページを作ることができるので便利です(例えば、現在時刻を出力!)このようなページのことを「動的ページ」と言います。反対に毎回変わらないページを「静的ページ」と言います。
Webリクエストにパラメータを渡したくなったら
CGIによって「動的ページ」が実現できると、プログラムにパラメータを与えたくなってきます。そこで、初め、ファイル名の後ろに?を付けてその後ろにパラメータをつけていく方法が考えられました。
GET xxx.html?id=1
この方法はとても便利です。現在でも、Googleの検索結果を
https://www.google.com/?q=Java
のように表すことができます。
しかし、問題がありました。
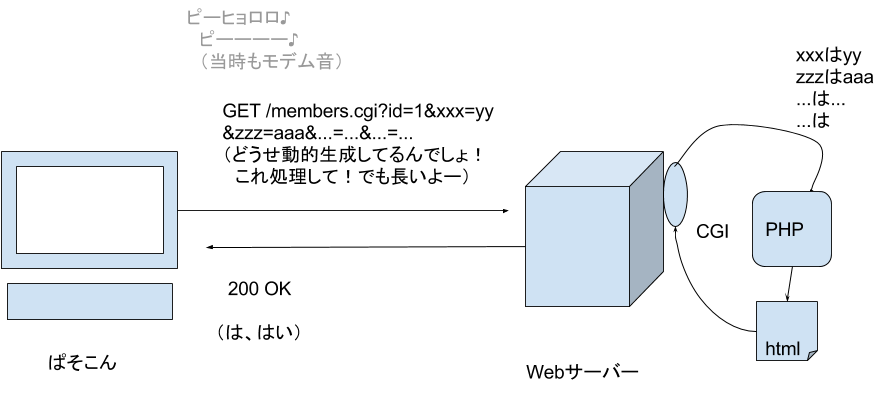
- 大量のデータを送ろうとすると長くなりすぎる
そこで、POSTという別の方法が考えられました。これは、ファイル名を指定した後、一行空行を開けてパラメータを送るという方法です。
POST /hello.cgi
name=taro&age=20&country=Japan&.......
これによって、非常に大量の情報が遅れるようになったので、Webを使って「ご注文フォーム」が作れるようになりました。Amazonのようなネット通販の始まりです。
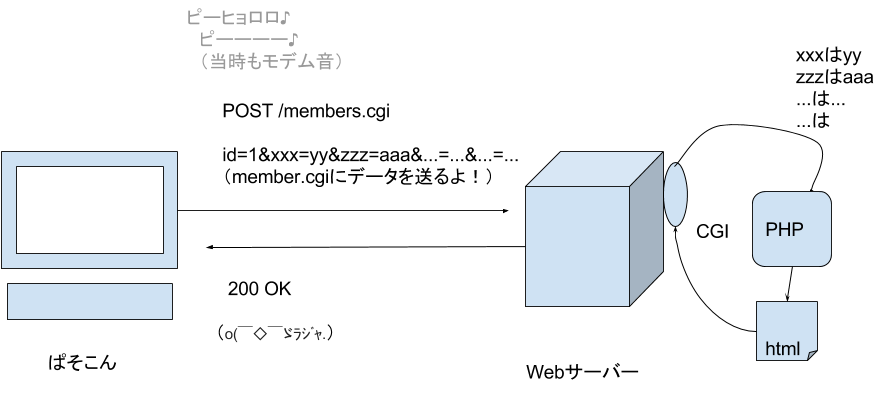
時代の流れとともに、いろんな情報を送りたくなってきた
時代は流れ、WWWは論文の配信だけにとどまらず、通販やゲームのようなあらゆる用途で使用されるようになってきました。しかも、文書だけでなく、画像、音声、映像、様々な種類のデータを配信するようになります。
そうすると、HTTPもどんどん複雑になります。現在はHTTP 1.1というバージョンが主流で、次のようにいろんな情報を送ります。
GET http://www.susumuis.info/
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding:gzip, deflate, sdch
Accept-Language:ja,en-US;q=0.8,en;q=0.6
Cache-Control:no-cache
Connection:keep-alive
Cookie:
Host:www.susumuis.info
Pragma:no-cache
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36
レスポンスは
200 OK
Cache-Control:no-cache, must-revalidate, max-age=0
Connection:keep-alive
Content-Encoding:gzip
Content-Type:text/html; charset=UTF-8
Date:Mon, 04 Jan 2016 02:57:30 GMT
Expires:Wed, 11 Jan 1984 05:00:00 GMT
Pragma:no-cache
Server:nginx
Transfer-Encoding:chunked
Vary:Accept-Encoding
<!DOCTYPE html>
<html>
〜
(省略)
</html>
こんな風に、色々な情報が付与されてきます。Accept:のようにHTTPリクエストに付与される付加情報を「リクエストヘッダ」と呼びます。Cache-Control:のようにHTTPレスポンスに付与される付加情報を「レスポンスヘッダ」と呼びます。
Content-Typeヘッダについて
レスポンスヘッダに次の部分がありました。これは「コンテンツタイプ」といって、とても重要な情報です。
Content-Type:text/html; charset=UTF-8
text/htmlは、「MIME Type」と呼ばれる情報です。これは、レスポンスするデータの種類を表しています。MIME Typeには次のようなものがあります。
| MIME Type | 意味 |
|---|---|
| text/plain | テキスト文書 |
| text/html | HTMLページ |
| image/jpeg | JPEG画像 |
| text/javascript | JavaScript |
| application/xml | XMLデータ |
| application/json | JSONデータ |
アプリとWebサーバー
本来、Webサーバーは、WebブラウザーにWebページを配信することを目的としたサーバーでした。しかし、時代は流れ、Webブラウザだけでなく、HTTPプロトコルさえ使えれば、Webサーバーと通信ができる特性を利用して、スマートフォンアプリなどのプログラムがサーバーと通信をするために大変広く使われるようになりました。
HTTPがシンプル・高機能・有名で便利だったからです。
プログラム同士の通信では、もう、HTMLを使用する必要はありません。HTMLは人間に見た目を提供するためのフォーマットだからです。
プログラムで使う場合は、XMLまたはJSONというデータ形式が使われます。
XMLの例
<items>
<item>
<name>アイテム1</name>
<price>1000</price>
<image>xxxxxx.jpg</image>
</item>
<item>
<name>アイテム2</name>
<price>1240</price>
<image>yyyyyy.jpg</image>
</item>
</items>
JSONの例
{
{
"name": "アイテム1",
"price": 1000,
"image": "xxxxxx.jpg"
},
{
"name": "アイテム2",
"price": 1250,
"image": "yyyyyy.jpg"
}
}

サーバーはどうなっているの?
アプリ側から、サーバーの内部を意識する必要はありません。しかし、サーバーは通常次のように作られています。
Webサーバー
Apacheや、IIS、Nginxというようなサーバーソフトが使われます。
サーバープログラム
PHPや、Javaや、Rubyで書かれています。その間にアプリケーション・サーバーというソフトウェアが動いている場合もあります。
DBサーバー
Webサーバーは非常に大量のデータを扱うため、DBサーバーという専用のソフトウェアが使われることが大変多いです、MySQL、PostgreSQL、Oracleなどが有名です。
キャッシュサーバー
DBサーバーは非常に便利ですが、遅いという問題があります。そこで、高速化の目的で、別途キャッシュ用のサーバーが用意されていることがあります。Redis、Memcachedなどが有名です。
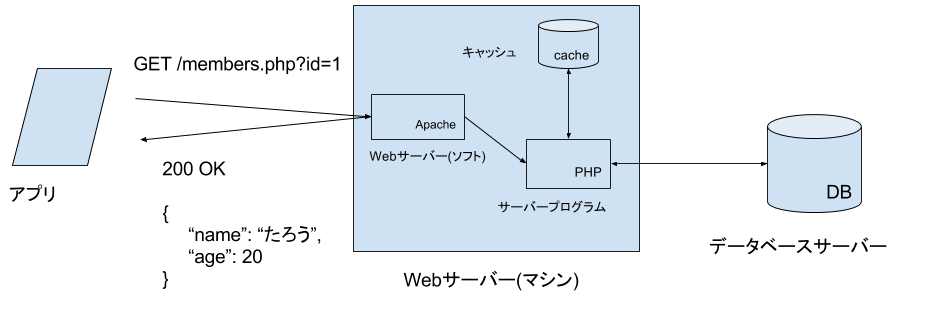
まとめ
このように、もともと論文を配信するためであったWebサーバーはとても便利なので、アプリのデータをやり取りするために使われるようになりました。
Webサーバーは今やとても複雑な仕組みですが、呼び出す側としては、HTTPプロトコルさえ分かればやり取りができるので、内部まで意識しなくても大丈夫です!
それでは、次回は実際にアプリから呼び出す方法を説明していきます。