これは Mayaa Advent Calendar 2015 の24日目です。昨日は「Mayaaの学び方・教え方」でした。
今日はクリスマスイブです!リア充が爆発している中、硬派な皆さんはMayaaアドベントカレンダーを読んでくださりありがとうございます。
クリスマスプレゼントとして、今日は徹底的にガチなことを書きます。
Mayaaのソースコードの読み方
さて、git cloneで落としましたか?
今日はこいつの読み方を説明します。準備は良いでしょうか?
プロジェクト構成を眺める
プロジェクトフォルダをざっと見ると、
- src-api
- src-impl
2つのフォルダがあります。僕はこのようなフォルダ構成はMayaaしか知りません。試しにGoogleで「src-impl」と打ち込むと、Mayaaのソースが出てくるからMayaaの独特の構成かもしれません。
contect フォルダはライセンス情報や依存ライブラリ、Webアプリとして単体起動させるための設定情報などがあるだけで、ライブラリとしてあまり重要なものはありませんので、コードリーディング時は無視してよいです。
src-apiでAPI構成を知る
src-apiにはinterfaceが定義されています。つまり、src-apiに存在するインターフェースは何らかの方法で実装を交換可能になっているということです。
実装が交換可能ということは、独立した部品とみなされていると言って良いです。つまり、src-apiをざっと見れば、Mayaaがどんな部品によって構成されているかを知ることが出来ます。
パッケージ階層を見ると次のような構成であることが分かります。
- builder
- cycle
- engine
- provider
- source
Mayaa内部の用語なので、これだけ見ても、最初は慣れないと思いますが、そこで、Mayaaの処理する流れをざっと説明します。
engineはMayaa中心で起点と考えてよいです。
engineの中は、processorと、specificationに分かれます。specificationはmayaaファイルやテンプレートの定義情報をモデル化したものです。processorは、テンプレートエンジンがそのノードをどのように処理するかをオブジェクト化したものです。つまり、specificationによって組み立てられたprocessorがあればMayaaエンジンはHTMLを出力することが出来ます。
providerはアプリケーションスコープのリソースです。エンジンの設定や、各インターフェースの実装クラスの選択はここが担当します。そのため、Mayaaの設定はorg.seasar.mayaa.provider.ServiceProviderなのです。
sourceは、mayaaファイルやhtmlテンプレートなどユーザーが作成するソースファイルを抽象化しています。他のインターフェースに依存しませんが、実装上は、ビルド時にほぼ必ず使用します。
cycleは、リクエスト処理のコンテキストを扱います。リクエスト・レスポンス、現在処理中のノードといったスレッドローカルなコンテキストはここに格納されていきます。
builderは(主にsourceを元にして)SpecificationNodeを組み立てます。
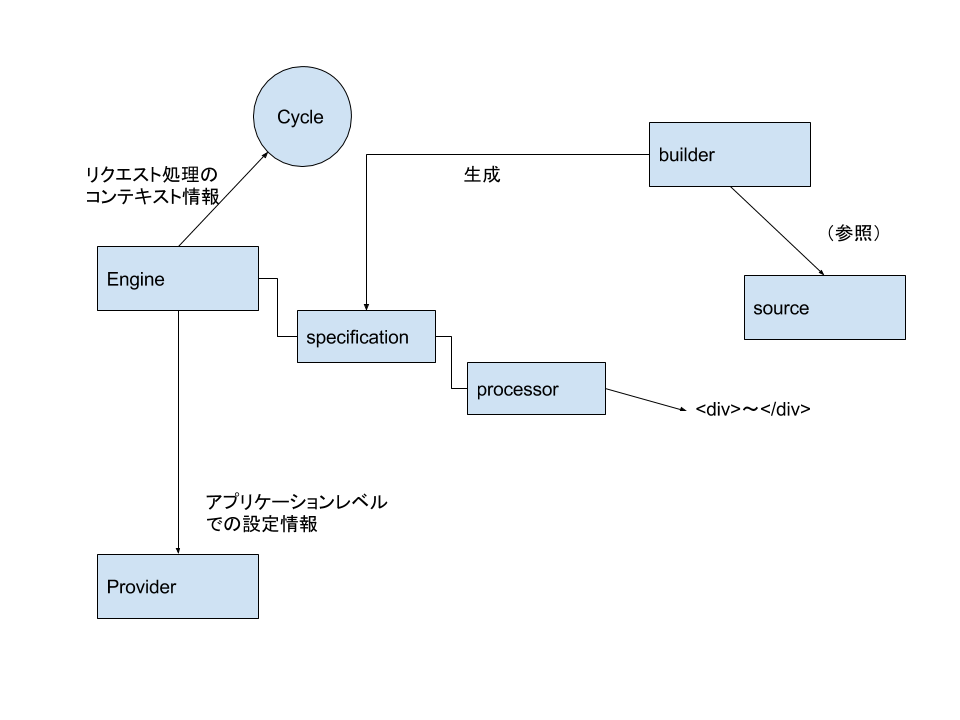
つまり、provider, cycleは事実上Engineを動かすのに必要ですが、何らかの方法でspecification/processorが構成できてしまえば、builder, sourceは切り離せるとも言えます。
継承の起点としてのインターフェースを理解する
次に、クラス階層から実装の作法を理解してみましょう。
こんなクラスが実装の起点に存在しています。
- PositionAware
- NodeTreeWalker
- ParameterAware
- ContextAware
- UnifiedFactory
これらをざっと眺めておくと後々実装を追いやすくなります。
実装クラスの起点はMayaaServletから
なんだかんだ言っても実装はMayaaServletから追い始めるのがベターです。
MayaaServlet#doServiceで、Cycleを初期化し、ProviderからEngineを取得して実行しているのが分かります。
EngineImpl#doServiceを追って行くと、EngineImpl#doPageServiceという大きなメソッドに行き着きます。ここが、一リクエスト分のレンダリング処理の主要部分です。ここを起点に、テンプレートの情報を取得し、各部品を実行することで、結果としてのHTML文書が出力しされます。
大枠を理解できたら後は部品ごとの設計を理解する
例えば、SourceDescriptorは内部でCompositeパターンになっています。Processorを理解するには、TemplateProcessorSupportという巨大なクラスの機能を理解する必要があるでしょう。
また、Rhinoスクリプティング機能は、cycle.script.rhino内に収められています。したがって、これと同等の部品を実装して、独自のCompiledScriptが実装ができれば、スクリプトエンジンをRhino以外に切り替えることもできます。
まとめ
Mayaaのソースコードは、各部品の独立性と抽象度が高く設計されています。このため、全体を各部品に切り離して考えることが出来、一部分を拡張したり、変更することが行いやすくなっています。
FactoryFactoryがある時点で、DIコンテナが普及する以前の香りがしますね。Seasarプロジェクトと言いながらSeasarに依存しないのは、このように独自にフレームワークを作っているからなのです!また、今回は触れませんでしたが、内部には、GCの管理や、シリアライザーをガリガリいじったり、相当低レベルのこともしています。(それらを読んでいるととても勉強になります)
こういった低レベルな部分がソースを膨らませているとも言えます。何も知らないで読むと、溺れてしまいそうです。しかし、フレームワーク的なところ、低レベル過ぎるところは一旦置いておくと、読むべき範囲は限定されてきます。
ソースコードを読む動機というのは様々で、拡張したい時の他に、トラブルシューティングをするとき、パフォーマンスチューニングしたい時などいろいろあると思いますが、その時必要な範囲で読めるように、普段から慣れておけば、そんなに怖いものではありません。